Putting a Basic Playing Style Classifier to the Test
Any measure of playing style is only as good as what it can explain beyond player overall ability. If we apply this standard to playing style categories derived from basic match stats, how do they hold up?
In this latest of posts in a series addressing playing style I look at whether style categories derived from match stats can improve the predicted outcome of matches. These categories are derived from just four basic match statistics— ace rate, double fault rate, the difference in first serve won and second serve won percentages, and the average duration of points— that are about as far as one can go with these aggregate stats in measuring aspects of the way a player performs apart from the skill of their performance.
I previously obtained effects for ATP slam players on each of these measures and found that, based on k-means, 10 clusters were a reasonable choice for reducing the within-cluster variance.
But those results don’t tell us whether the clusters are doing anything useful. What would make them useful? If we believe style matchups matter, then we would expect these clusters to improve our expectations for at least some style clashes.
Do they?
To put the style matchups to the test, we can start with our standard prediction of choice. In my case, that will be a prediction based on surface-adjusted player ratings. That prediction is determined by the rating difference between player $i$ and player $j$, which we can call $D_{ij}$.
Now let’s suppose each matchup also has a style category. If player $i$ has style cluster $k_i$ and player $j$ style cluster $k_j$, and $J_k$ is a K-element vector that has the value 1 in the $k$th spot and is zero everywhere else, we can assign a style effect for that matchup, $\phi_{(k_i,k_j)}$, as $J_{k_i}' \Phi J_{k_j}$, for some K-by-K matrix of style parameters $\Phi$.
The logistic model to find the style effects is,
$$ log(p_{ij}/(1-p_{ij})) = \beta D_{ij} + \phi_{(k_i,k_j)}. $$
Since the effect $\phi_{(k_i,k_j)}$ should have a complementary effect for player $j$, that is, $\phi_{(k_i,k_j)} = -\phi_{(k_j,k_i)}$, we will only fit the model in terms of the lower triangle of $\Phi$, where $k_i \leq k_j$. With $K=10$, that includes 55 style effects.
I fit the above logistic model to all player matchups (among players competing at slams) who met at the challenger level or above between 2014 and 2017. I then applied those effects to adjust the standard match prediction for matches played in 2018. Of the 55 style matchups in the test data, there were 19 that showed improvement in the log-loss of the match predictions. However, as seen from the chart of the improvement below, the improvement was moderate for all but a handful of matchups.
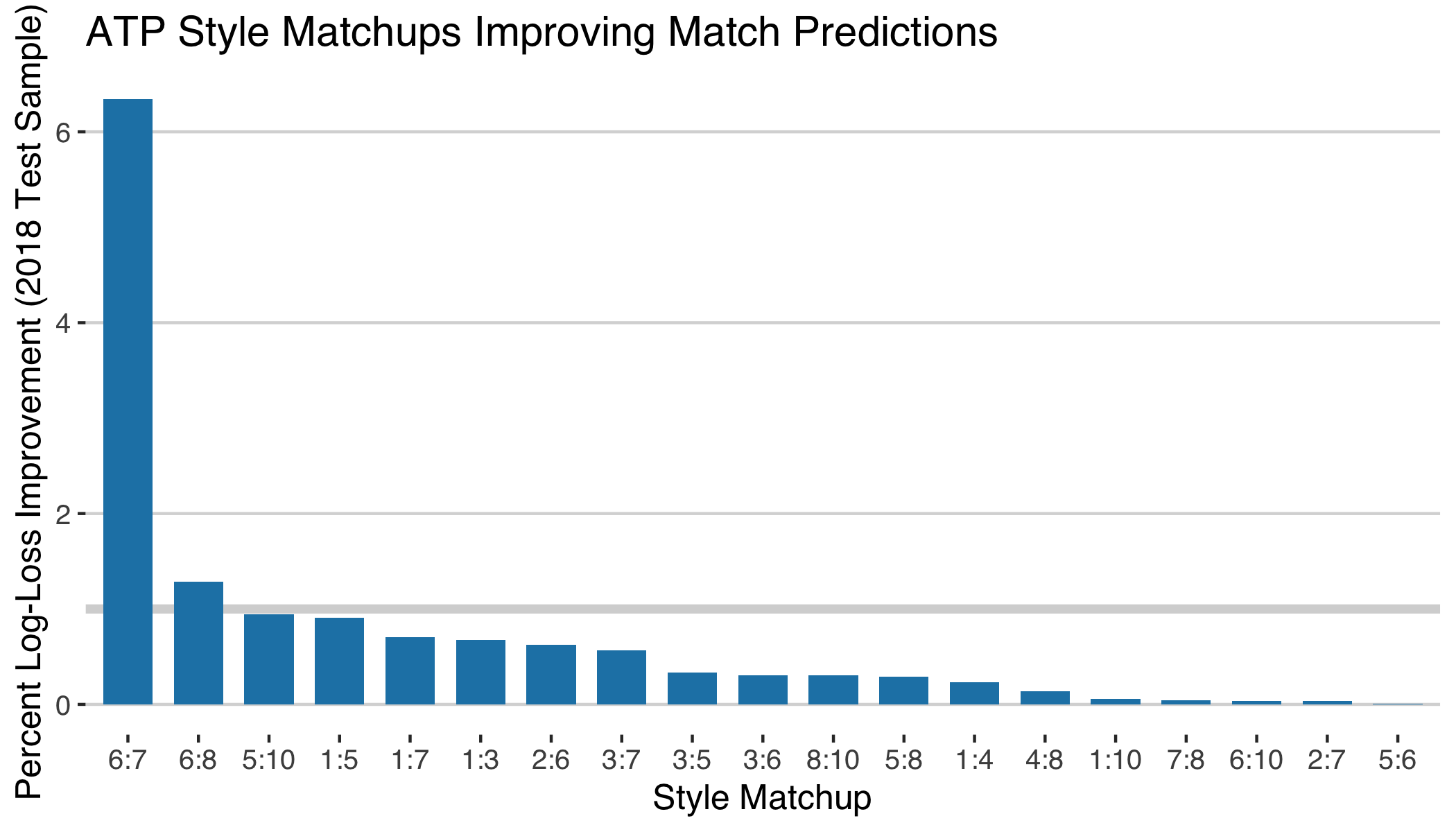
These matchups don’t have much meaning without some context. We can get our heads around these results by looking at some of the specific player-opponent matchups that fall in each of the most informative clusters and look at how the style adjustment would shift predictions in those cases.
Below is a sample of matchups from the 6:7 style group, which had the most overall predictive improvement of all style matchups. Three of the players landing in style cluster 6 are Ernests Gulbis, Feliciano Lopez, and Jeremy Chardy. There group is distinct for having above average serving power, above average accuracy on their second serve, a smaller than average gap between their points won on first and second serve, who tend to play at a quicker pace than average.
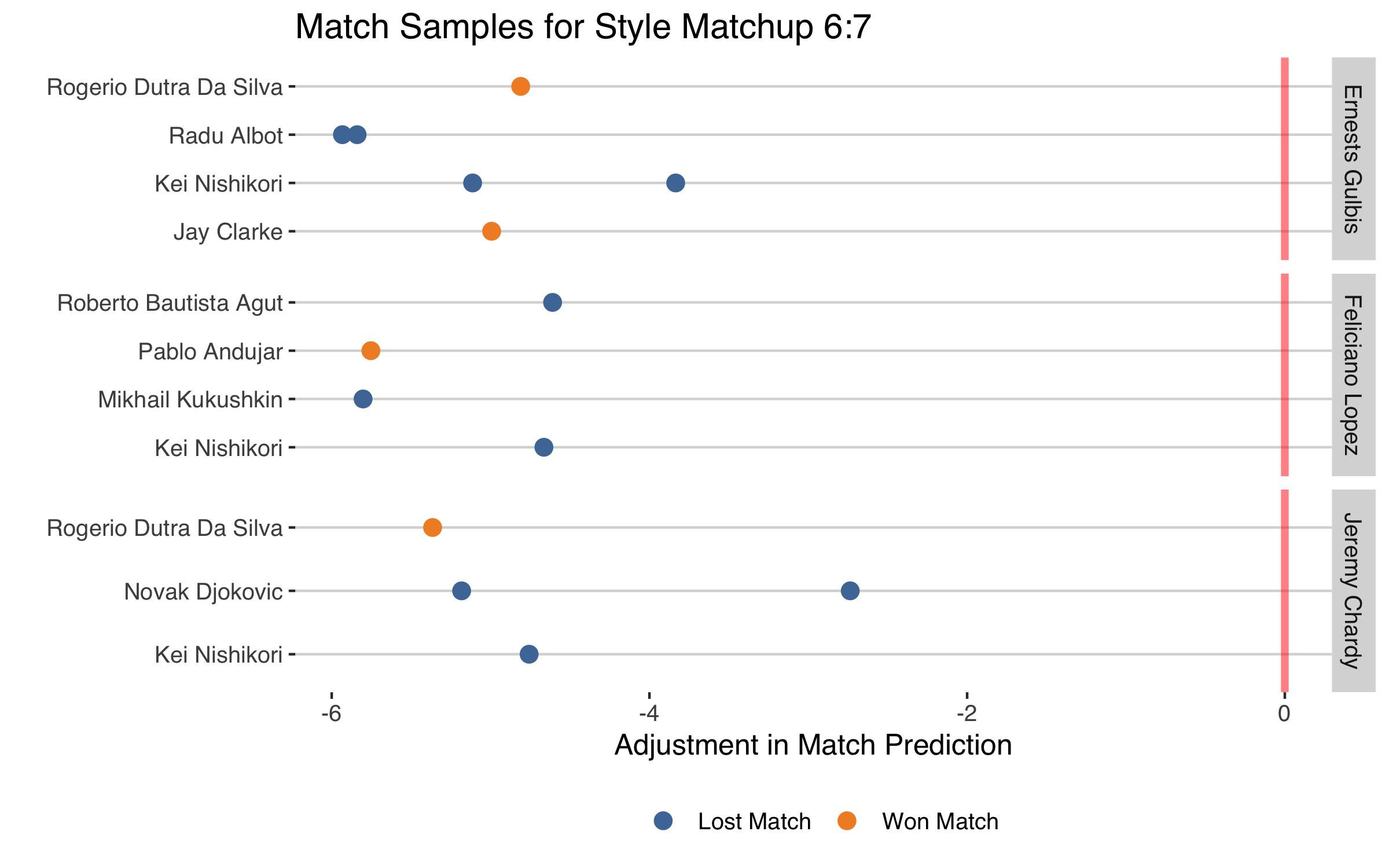
Style group 7, on the other hand, has less serving power, has a high double fault rate, has a high gap between their points won on first and second, and likes to grind more than the average player. This group includes players like Kei Nishikori, Rogerio Dutra Da Silva, and Novak Djokovic. The style effect for the clash between these players and group 6, doesn’t bode well for players like Gulbis, Lopez and Chardy. The style effect adjusts all of their standard predictions downward, which appears to have been the right direction more often than not.
Style group 8 is similar in many ways to group 7, the standout for them being a more powerful first serve on average but taking less risk on their second serve. Players from this group include Denis Istomin, Filip Krajinovic, and Philipp Kohlschreiber. Interestingly, the similarity in group 7 and 8 styles manifests in a similarly strong clash with group 6 players, of whom we can add Gilles Muller.

The clashes in this case result in less of a downward correction in general. Still the examples suggest that group 6 players are tending to worse more often than better against group 8 players.
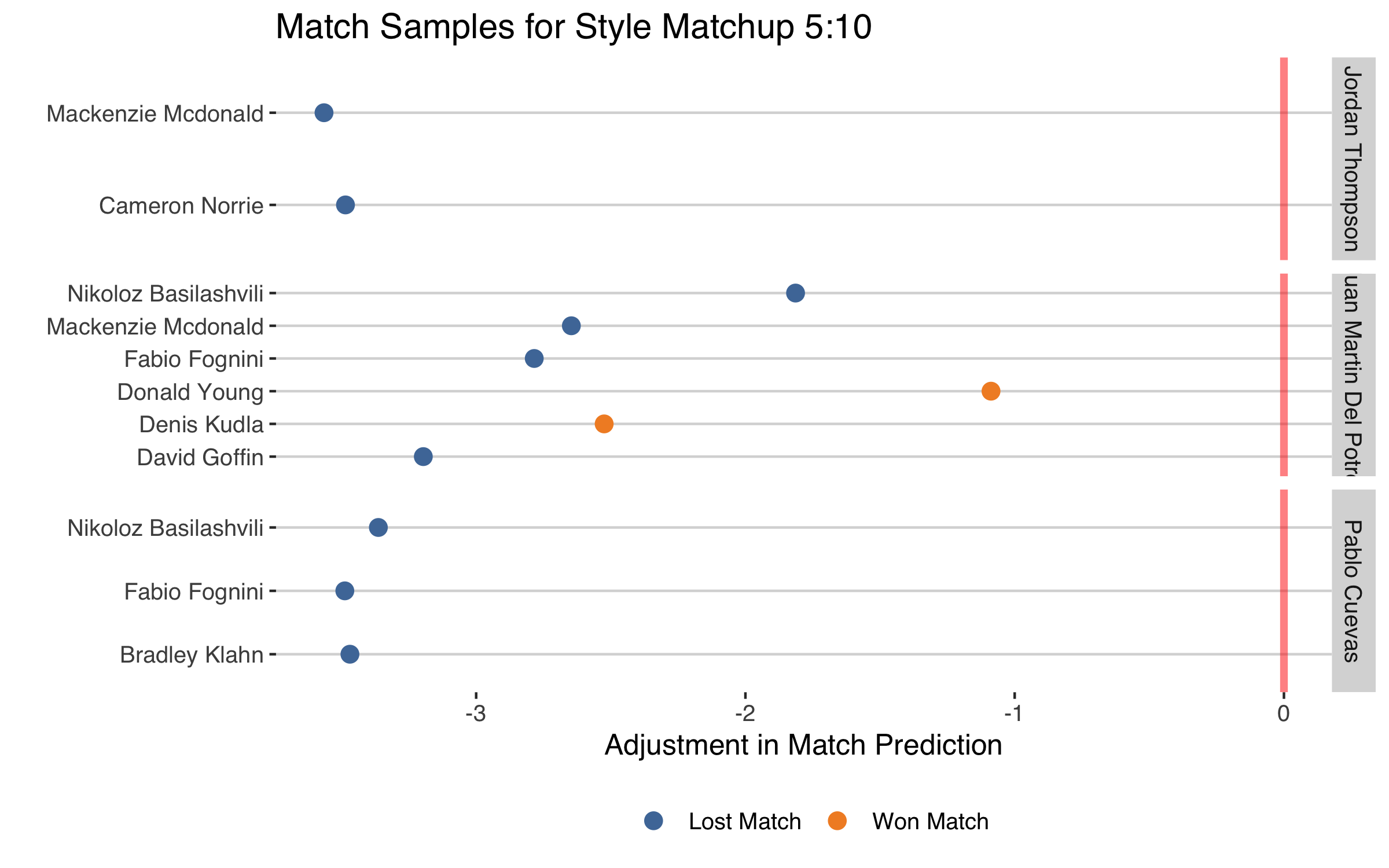
The next clash is between style group 5 and group 10 players, a matchup that had the 3rd most improvement in predictions in the test sample. Group 5 players are interesting in having a small gap between first and second serve performance without hitting a lot of aces. They are also the second slowest-paced group on tour. Three of the players that fall in this style category are Jordan Thompson, Pablo Cuevas, and Juan Martin Del Potro.
Style group 10 is the opposite in all respects. Having a high rate of aces, a bigger than average gap in first and second serve performance, and playing some of the fastest-paced tennis on tour. Players in this group include Fabio Fognini, David Goffin, and Mackenzie McDonald.
The match sample below shows that this style matchup isn’t a good one for group 5 players, whose results tend to take a hit when put up against the aggressive, fast-paced style of group 10 players.
In this first look at the predictive value of style categories based on the simplest types of aggregate match statistics, there are some positive results. At least a handful of matchups show demonstrable gains in their expectations. And the sample of matches that we’ve reviewed suggest that the style categories are grouping players in a reasonable way. It would be interesting to see how adding in some more detail about players; like height, handedness, type of backhand, for example; could further improve these results. From what we can see here, it seems building on this direction could be a worthwhile new way of approach head-to-heads.
