Tennis Enters the Big Leagues of Sports Analytics
Last week many of the sports world’s most innovative number crunchers converged in Boston at the MIT Sloan Analytics Conference. The 10th anniversary of the two-day nerd fest attracted 3,900 attendees and some of the heaviest hitters in sports stats, including Bill James, Nate Silver, and Mike Zarren.
One of the traditional features of Sloan is the research competition. In true sporting fashion, this is a multi-stage, single-elimination tournament that pits the top research innovations in sports analytics against each other. The handful of submitted papers that advance to the final round, go head-to-head in a TED-style showdown on the last day of the conference. The author presenting the best innovation, as judged by a panel of experts, is revealed in the closing ceremony of the program.
 Caption: Patrick Lucey accepts alpha award at 2016 Sloan from co-founders Daryl Morey and Jessica Gelman
Caption: Patrick Lucey accepts alpha award at 2016 Sloan from co-founders Daryl Morey and Jessica Gelman
As you might imagine, the Sloan research competition has historically been dominated by advances in baseball and basketball analytics. And only the most risk-seeking gamblers in attendance would have bet on any change from that tradition this year. Yet, in an upset on par with Roberta Vinci’s defeat of Serena Williams at the 2015 US Open, a paper on tennis, entitled “The Thin Edge of the Wedge”, took the 2016 top research prize.
To say that tennis was the underdog in this competition is an understatement. Only 4 years earlier ESPN said that tennis was in the analytical dark ages. In the same year that pessimistic take appeared, Sloan put together a panel of Paul Annacone, Craig O’Shannessy, and Todd Martin to discuss how tennis could get its own Moneyball. As noted by Neil Paine of FiveThiryEight, even with these efforts, not one tennis paper had ever advanced to the final stages of the first 9 years of the Sloan competition. So, the fact that the “The Thin Edge of the Wedge” was not only a contender this year but actually came out on top is a as much a victory for tennis as it is for the paper’s authors.
So what is the “The Thin Edge of the Wedge”? And how did it help tennis finally hit one out of the park, statistically speaking?
First, the Team
Since the HawkEye challenge system was introduced in 2006, tennis has been sitting on an untapped gold mine of potential insights into the current game. Yet, the general lack of access to these data has made realizing this potential difficult. Although slow, we are starting to see some progress in this area as governing bodies are brokering deals with HawkEye to use at least some of the tracking data for research purposes. It’s not the open model the MLB or NBA has taken with respect to data, but it is a start.
Tennis Australia has been one of the most proactive governing bodies in this regard. In fact, it was Tennis Australia’s acquisition of trajectory data and partnership with Patrick Lucey’s analytics team at Disney Research (Lucey has since moved on to STATS LLC) that were the first steps in the story behind “The Thin Edge”.
However, the work would have never been possible if Lucey’s team hadn’t made the smart choice some years ago of recruiting PhD student Xinyu (Felix) Wei to intern with their group. While completing his doctoral studies at Queensland University of Technology, Wei has worked with Disney Research (in collaboration with Tennis Australia and the Australia Institute of Sport) on problems in computer vision that have included several applications in tennis. Though largely unrecognized until Sloan 2016, history might ultimately say that these were some of the earliest works in a revolution in the way we think about and consume tennis.
What is “The Thin Edge”?
In simplest terms, “The Thin Edge of the Wedge” presents a model to predict how likely it is that a shot in a tennis match will be end the point. The title is a play on the idiom that connotes a small event that ushers in a game-changing development (the phrase is supposed to have originated from a small device used to split wood in logging). Wei and colleagues use the idiom to refer to the tipping point in a rally, where the outcome of the exchange shifts heavily in one player’s favor. By quantifying the probability that a shot will end the point, their model is the first that can actually identify these tipping points and, in doing so, identify the most influential shots in a rally.
Predicting Shot Outcomes in Tennis
The basic challenge that Wei and team faced in developing “The Thin Edge” model was 1) the selection of predictors and 2) the choice of model form that would be flexible enough to handle the complex ways these predictors might influence the outcome of a shot.
We all probably have some idea of the factors that would distinguish winning shots from all other shots: depth, speed, spin, opponent position, etc. The full set of predictors that Wei and his co-authors considered are listed in the table below. You can see that they fall into four types, listed from factors that are most to least directly linked to the current shot.
| Type | Predictor |
|---|---|
| Current Shot Descriptor | Location of start of shot |
| Current Shot Descriptor | Location where shot impacts the court |
| Current Shot Descriptor | Average speed of shot |
| Current Shot Descriptor | Court position of both players at the start of the shot |
| Comparison of Previous and Current Shot | Ratio of average shot speeds |
| Comparison of Previous and Current Shot | Ratio of player distance from baseline (depth) |
| Comparison of Previous and Current Shot | Ratio of lateral distance covered |
| Style | Frequency of single shot types from shot dictionary |
| Style | Frequency of shot combinations from 2-3 shot combination dictionary |
| Context | Number of shots in the rally |
| Context | Set score |
| Context | Point score |
The current shot descriptors include some of the most typical characteristics of the current shot. Together, these factors tell you exactly where the shot started, landed, how fast it was going, and where each player was positioned at the start. You might think with all of this information you should already be able to make a very good guess as to whether the shot ended the point (e.g. fast on the line away from the opponent versus slow and in the service box near to the opponent). In fact, these factors alone had a prediction accuracy for recent Australian Open matches of 60%, which is okay but far from spot on.
It turns out that there is more to what makes a shot decisive than these basic descriptors can tell us. One way that Wei and authors found that they could make better predictions was if they considered more of the history of the rally. Specifically, they looked at how the speed, depth of the player’s from the baseline, and the distance covered between the current shot and the one the opponent hit just before might influence the winningness of the current shot. Wei and colleagues refer to these factors as “dominance features”. The reasoning here is that how effective a shot will depend not just on its characteristics but how these characteristics compare to what the opponent has just been able to do. A Federer backhand fired down the line might have a very different outcome if it is in response to a counter-punching crosscourt shot versus an attacking approach shot.
Contrasting these basic features of the current and previous shot did improve predictions, though not hugely (gain of 2 percentage points).
So far, all of the features in the model ignore the specific effectiveness of the player, which means that the chance a 100 mph shot to the corner of the deuce court ended the point would essentially be the frequency that shots like that ended the point for any of the top 10 players (at the time the research was done), even if the forecasted shot was actually hit by Nadal, for example. But even among the best players, we might expect quite a range in how effective their shots are, even if they look fairly similar when watered-down to a few key descriptors.
Accounting for player effects is the trickiest problem Wei and team tackled in building their prediction model. What makes it tricky is that, although they group used about 9,300 to train the model, this is still not enough to get robust, player-specific estimates for every shot they might observe in a match. Instead of relying on potentially shaky or inestimable player estimates, Wei and his co-authors developed descriptions of player style.
Style is one of those things we all talk about but would struggle to put numbers to. Most consider David Foster Wallace’s essay “Roger Federer as Religious Experience” as one of the most accurate descriptions of Federer’s style. Yet how would you go about condensing that into something that could be fed into a mathematical model?
Wei and team propose one way of quantifying playing style that I think ends up being one of the richest and most interesting parts of the paper. The approach starts with the development of a shot “dictionary”. (As an aside, I really like the choice of “dictionary” here because there is something romantic about thinking of shots in tennis as a vocabulary and the way a rally unfolds as a kind of conversation between players. But getting back to some cold, hard numbers…) The actual dictionary is a collection of shot trajectories that have been grouped using K-means clustering to find a basic lexicon of shots. The final dictionary in the paper includes 50 single, two-shot and three-shot trajectories.
Once the dictionary is in hand, Wei and co-authors describe a player’s style as the percentage that player uses each shot of the dictionary. As far as I understand it from their methods, this means that each player has a 50-element vector of percentages that goes into the model and acts as a kind of playing signature for that player. All players contribute to how a shot influences the baseline effectiveness, but Wei and team still get something like a player-specific estimate because each player will have a distinct set of weights defining his signature.
Below, the authors show one example of how the progression in an exchange of shots differs with the inclusion of player style. On the left panel, the predictions treat all shots like they came from any random player in the top 10. In this case, the win probability is about 50-50 throughout. The panel on the right includes the style of Nadal and Djokovic in an effort to make the rally more specific to this particular pairing. The result is to give Nadal an edge in the first two shots and the strong favorite by the final fourth shot.
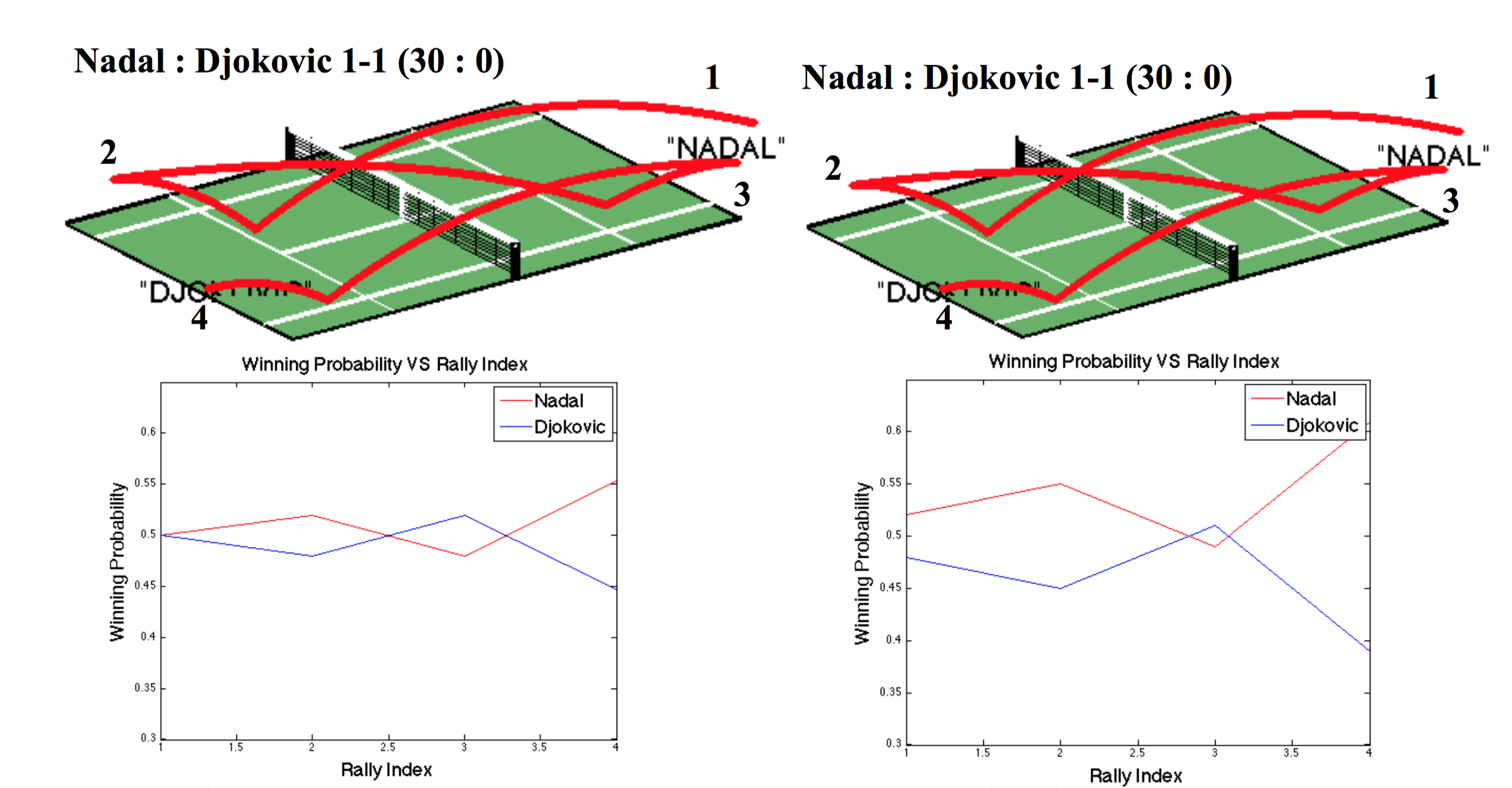 Caption: Figure 4 of Wei et al. "The Thin Edge of the Wedge"
Caption: Figure 4 of Wei et al. "The Thin Edge of the Wedge"
Overall, these kind of style adjustments had the biggest improvement in prediction accuracy of all of those considered in the paper, raising the performance by 5 percentage points.
The final set of predictors tested account for the context in which shots occur. These included rally count, point score and set score. This added another 2 percentage points to the prediction performance of the model, ending with an overall accuracy of close to 70%.
The actual framework used to estimate the shot outcome from a set of predictors (the second of the two major parts of the model development outlined above) was a Random Decision Forest. This is a tree-based approach, which is best suited for non-linear classification problems.
Why Did “The Thin Edge” Win?
Much like the decision-making of a papal conclave, we will probably never really know why the Sloan panel of experts chose one paper to win the research competition over the others. But we do know from past award results, that methods with tracking data have been popular. “The Thin Edge” has to represent one of the most advanced uses of HawkEye data and the first shot-level prediction model in tennis. The panelists must have seen the novelty in this and appreciated the promise that it holds as a tool for opponent strategizing and broadcasting analysis.
Where Do We Go From Here?
As enthusiastic I think we should all be about the advance “The Thin Edge” has made for tennis analytics, it is also important to recognize some aspects of the methods that were unclear and many additional questions concerning shot prediction that remain to be explored. Below are a few needs for clarification and questions for further research that occurred to me when reading this research.
-
How exactly is style included in the model? From the description in the paper, I was 90% confident that the 50-element feature vector of shots was how style was accounted for in the model. The other 10% thought that it might be a similarity measure between the player and opponent in the given match.
-
Does the model include player and opponent style adjustment? This was another aspect of the style adjustment that wasn’t clear.
-
What does the shot dictionary look like? As I read about the 50-item dictionary, I really wanted to have a shot-by-shot description of its contents. The lexicon of the top game in some ways seems as interesting as the model that builds on it. Although the authors provide figures of a subset of these, I don’t believe all 50 are included. Also, there was no way I could find to link the shot number in player style signatures to the figures that were shown.
-
Does the Random Decision Tree out perform other machine learning approaches? parametric approaches? It is unclear if Wei and team considered other modeling approaches before settling on the Random Decision Tree. In particular, if a parametric model like logistic regression gave reasonably similar prediction performance it would have the additional advantage of allowing an interpretation of the regression coefficients to see which among the features were the most important and how.
-
Does history beyond the previous shot matter? With prediction modeling, one always wonders if there are better features out there that have been omitted. In the case of the model in “The Thin Edge”, the omitted information that I wonder about (in addition to the physical features of the shot like spin) is the history of the rally, previous points, event previous games and matches. Could it really be the case that a player’s effectiveness and shot choice is dedicated only (as the model assumes) by the previous shot?
-
How to allow player-specific shots? If I understood the use of player style, it would seem to adjust the baseline for every shot with a constant shift up or down in point win probability. If so, I wonder if player-specific effects in the predictors could be more directly incorporated with the use of a shrinkage estimator so that, when enough information is available something different from the average effect could be used to tailor the shot effectiveness to the particular player who made the shot.
-
Would the dictionary grow with more players? The dictionary of shots in “The Thin Edge” is based on the player of the top 10 players only. If we expand the dictionary construction to a larger segment of the tour, do we think the lexicon will basically stay the same? or will there be some shot types or shot combinations that might be in the lexicon of lower-ranked players that aren’t shown here?
-
Can this approach generalize to the rest of the tour? to the WTA? The development and testing of Wei and team’s shot prediction model is based on the top 10 male players only. It is unclear how much data from another player would be considered sufficient for their inclusion. Also, if extended to lower-ranked players or to the WTA, will the predictions be as accurate?
-
What about prediction uncertainty? Any estimate comes with uncertainty. The authors of “The Thin Edge” don’t suggest how this could be measured or reported.
-
Could a similar model based on data from the Match Charting Project be built? and how would its performance compare? The Match Charting Project (MCP) is a volunteer effort to code shot-by-shot information of professional tennis matches. Although less granular that the ball tracking and player position data, the MCP is the richest description of shots that is available to the public. For the very reason that MCP data is free and open to everyone, it would be worthwhile to see what or how to get this data source to a point where it could be used to build a shot prediction model that could compete with the model in “The Thin Edge”.
So much remains to be explored that I hope one of the outcomes of the surprising win of “The Thin Edge” at Sloan is to catalyze more tennis researchers to get involved in this and related areas of research. Let’s not look back at this win as a fluke but rather a breakout moment before a sea change in the way statistical thinking is used in tennis.
